It just occurred to me that there is a strong correlation between the hardest nuance to get (or grok, as the saying goes) about REST and RDF.
With RDF, there is the pervasive Clay Shirky misconception that the semantic web is about one large-ontology-to rule-them-all. I've made it a point to start every semantic web-related presentation with some background information about Knowledge Representation (yes, that snow-covered relic of the AI winter). 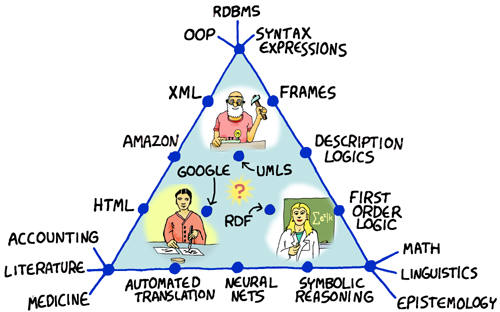 My favorite initial read on the subject is "How To Tell Stuff To A Computer - The Enigmatic Art of Knowledge Representation". As a follow-up, I'd suggest "What is a Knowledge Representation?" .
My favorite initial read on the subject is "How To Tell Stuff To A Computer - The Enigmatic Art of Knowledge Representation". As a follow-up, I'd suggest "What is a Knowledge Representation?" .
The thing that we miss (or forget) most often is that formal knowledge representations are first about a common syntax (and their interpretation: semantics) and then about the vocabularies you build with the common syntax. A brief read on the history of knowledge representation emphasizes this subtle point. At each point in the progression, the knowledge representation becomes more expressive or sophisticated but the masonry is the same.
With RDF, first there is the RDF abstract syntax, and then there are the vocabularies (RDFS,OWL,FOAF,DC,SKOS,etc..). Similarly (but more recursively), a variety of grammars can each be written to define a distinct class of XML documents all via the same language (RELAX NG, for instance). An Application Programming Interface (API) defines a common dialect for a variety applications to communicate with. And, finally, the REST architectural style defines a uniform interface for services, to which a variety of messages (HTTP messages) conform.
In each case, it is simplicity that is the secret catalyst. The RDF abstract syntax is nowhere as expressive as Horn Logic or Description Logic (this is the original motivation for DAML+OIL and OWL), but it is this limitation that makes it useful as a simple metadata framework. RELAX NG is (deceptively) much simpler than W3C XML Schema (syntactically), but its simple syntax makes it much more malleable for XML grammar contortions and easier to understand. The REST architectural style is dumbfounding in its simplicity (compared to WS-*) but it is this simple uniformity that scales so well to accommodate every nature of messaging between remote components. In addition, classes of such messages are trivial to describe.
So then, the various best practices in the Semantic Web canon (content negotiated vocabulary addresses, http-range14, linked data, etc..) and those in the REST architectural style are really manifestations of the same principle in two different arenas: knowledge representation and network protocols?